HTML5とは何か
技術的考察
HTML5でHTMLを記述するに当たっては、当然、「新たに採用もしくは変更された要素や属性をどのように使うのか」が、焦点になります。
2010年前半でHTML5が話題に上ったとき、そこでは動画をブラウザ自体で再生できるようにするvideo要素の存在が、Adobe Flashとの対比で注目されていました。また、それ以前からもスクリプトなどを使って動的に画像をブラウザ上で描画できる、canvas要素なども関心を集めているようです。実際、遅ればせながらcanvas要素に対応したIE 9 Betaが登場した際には、canvas要素を効果的に採用した協賛サイトが多数紹介されています。
こうした、動的で応答性に優れた「Webアプリケーション」をサポートすることも、HTML5の目的になっていますが、私自身は、オーソドックスな文章主体のWebサイト作成を志向しているため、やはりオーソドックスな文書構造の定義に関心を持っています。ですから、私の主要な関心は、「セクション」というカテゴリーに分類された、文章のアウトラインを定義する要素を、仕様に従って正しく記述することにあります。
要素の分類とコンテンツ・モデル
この、セクションも含め、HTML5では要素を次のようなカテゴリーに分類しています。
- メタデータ・コンテンツ(Metadata content)
- フロー・コンテンツ(Flow content)
- セクション・コンテンツ(Sectioning content)
- 見出しコンテンツ(Heading content)
- フレーズ・コンテンツ(Phrasing content)
- 組み込みコンテンツ(Embedded content)
- インタラクティブ・コンテンツ(Interactive content)
これらのカテゴリーの関係性は、以下の図で表されています。
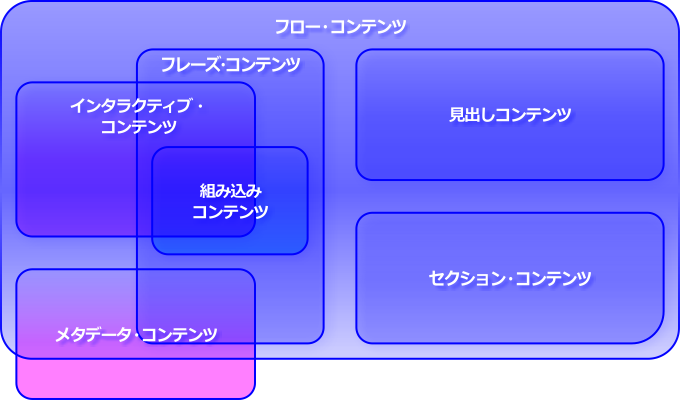
出典はhttps://www.w3.org/TR/2010/WD-html5-20101019/images/content-venn.svg
{kind=link}
その上で、HTML5では「ある要素の中にどの要素が入れられるのか」を、コンテンツ・モデルとして定義しています。
このため、正しいHTML5を書くためには、各要素がどのカテゴリーに分類されているかとともに、含めることのできる要素内容を把握しなければなりません――と、唐突に言われても、このモデルをすぐに理解するのは難しいでしょう。
従来の要素の定義
もちろん、従来までのHTMLやXHTMLでも、要素の入れ子関係には「インライン要素はブロックレベル要素の中に入れなければならない」という大原則がありました。たとえば、a要素をbody要素の直接の子要素として書いてはいけません。
<body>
<a href="#">文字列</a>
</body>
また、これは「インライン要素にブロックレベル要素を入れてはならない」ということでもあります。
<a href="#"><p>文字列</p></a>
品行方正なa要素の書き方は、p要素のような何らかのブロックレベル要素の入れ子にすることです。
<body>
<p><a href="#">文字列</a></p>
</body>
まあ、インライン要素というのは、文中の単語や文字列といったものを表すので、それらは段落(ブロックレベル要素)の中に入れなさい、という単純至極な道理です。
しかし、ブロックレベル要素同士の話になると、少し面倒になります。例えば見出しを表すh1要素はその中にもちろん文字が入れられます。文字が入るということは、インライン要素も入れられます。では、p要素を入れられるでしょうか? それは無理です。見出しは、それでひとつの段落として完結するようになっていて、他の見出しや本文の段落からは独立しています。ですから、こうしたブロックレベル要素同士の入れ子は作れません。
<body>
<h1>
<h2>
<p>文字列</p>
</h2>
</h1>
</body>
では、「ブロックレベル要素にブロックレベル要素を入れてはならない」と言い切れるのかというと、そうでもありません。たとえば、複数のブロックレベル要素を囲むことができるブロックレベル要素として、div要素があります。div要素の中には、body要素内に入れられるものであれば、何でも入れ子にできます。
<body>
<div>
<h1>見出し1</h1>
<div>
<h2>見出し2</h2>
<p>文字列</p>
</div>
</div>
</body>
また、リストを表すul要素やol要素の中で、リスト項目を表すli要素の中にも、ほとんどの要素を入れられます。一方で、li要素の中にli要素は入れられません。同様に、ul要素やol要素の中に入れられるのは、li要素だけです。
<body>
<!-- 正しい書き方 -->
<ul>
<li>項目</li>
<li>
<h1>見出し1</h1>
<p>文字列</p>
</li>
</ul>
<!-- 誤った書き方 -->
<ul>
<h1>見出し1</h1>
<li>項目
<li>項目</li>
</li>
</ul>
</body>
HTML5のコンテンツ・モデル
こうした様々な細則は、たぶん、HTMLの記述に慣れてくればおのずと理解できるものですが(私の場合は「HTML&XHTML&CSS辞典(大藤幹著/秀和システム発行)」という本で学びました)、HTML5では、こうした関係を論理的に明示したいという欲求に駆られたのでしょう。博物学的に分類し系統を定め、関係性の網の目に捉えようというわけです。
その大まかな前提となる各カテゴリーの定義は、
- メタデータ・コンテンツはhead要素内に入れる画面に表示されない要素
- フロー・コンテンツはbody要素内に入れる画面に表示される要素
- フレーズ・コンテンツは段落の中に組み込まれるの要素(従来のインライン要素)
ということになります。そして、
- セクション・コンテンツは自身に段落を組み込める要素
- 見出しコンテンツは見出しそのもの(これは簡単)
であり、再びフロー・コンテンツは、その他の段落的なものも含めた画面に表示される要素(これはもう曖昧)すべて、ということになります。
こうしたカテゴリーの定義に基づいて、自身に含めることのできる要素内容と、自身を配置できる要素(場所)が決定されます。例えばp要素であれば、以下の定義になります
- 分類
- フロー・コンテンツ
- 含めることのできる要素内容
- フレーズ・コンテンツ
- 配置場所
- フロー・コンテンツを配置できる要素
では、「フロー・コンテンツを配置できる場所」とはどこでしょうか? その大元はbody要素ですが、フロー・コンテンツを要素内容に入れられる要素も「フロー・コンテンツを配置できる場所」になります。それがコンテンツ・モデルという訳ですが、これは先のコンテンツの相関図で一目瞭然――というものではなく、要素個別の定義を確認していかなければなりません。
その例を、フレーズ・コンテンツであると思われるa要素で見ていきましょう。a要素の定義は、以下のようになっています。
- 分類
- フロー・コンテンツ、フレーズ・コンテンツ、インタラクティブ・コンテンツ
- 含めることのできる要素内容
- インタラクティブ・コンテンツを除くa要素の親要素に入れられる要素
- 配置場所
- フレーズ・コンテンツを配置できる要素
まず、a要素は、フレーズだけでなく、フローおよびインタラクティブ・コンテンツでもあります。そして、「含めることのできる要素内容」の規定に従えば、a要素の中にp要素のような、旧来のブロックレベル要素を含めることができます。HTML5ではそれが可能になりました。
<div>
<a href="#"><p>文字列</p></a>
</div>
a要素を置ける場所は「フレーズ・コンテンツを置ける場所」(=インライン)ですから、例えばdiv要素を親として、その中に配置できます。そして、div要素内にはp要素も配置できますから、この場合の「a要素の親要素に入れられる要素」にp要素は当てはまります。故に、上記のコーディング例は正しい、ということになります。
ただし、p要素の中のa要素の中に、さらにp要素を入れるとそれは文法エラーです。
<p><a href="#"><p>文字列</p></a></p>
なぜなら、p要素の中に含めることのできるのはフレーズ・コンテンツだけなので、p要素の中にp要素は含められません。すなわち、上の例でのa要素の親要素はp要素なので、この場合のa要素の親要素に入れられる要素ではない、という理屈になるわけです。
なお、「インタラクティブ・コンテンツを除く」というコンテンツ・モデルの例外規定は、a要素でa要素を囲めない、a要素でinput要素を囲めない、といったことです。マウスやキーボード操作に反応する要素が二重になると、内側の要素が操作できなくなるという、これは至極当然の理由です。
このように、HTMLは人為的に作られた言語であるにも拘らず、もしくは人間が作ったが故に、その関係には多様性が存在し、それを厳密に捉えようとすればするほど、整然とした系統で明快な関係が説明されるのではなく、例外を跡付けるために複雑に絡み合った定義が提示されることとなります。
HTML5のコンテンツ・モデルという概念は、たぶん、理解できている人には明快なのでしょうが、それを突然提示された人にとっては、論理の迷宮のように映るでしょう。結局のところ、初めに大まかな理解として従来の「インライン要素はブロックレベル要素の中に入れなければならない」を把握した上で、各要素を使用する際に、個別にHTML5の規定を確認していくしかないでしょう。
DOCTYPE宣言
こうした要素の分類を(いちおう)把握した上で、あとはタグを使って要素を記述するわけですが、従来はまずHTMLのバージョンと文書型(DTD)を明示する必要がありました。
HTML5では、この定義は無くなり、簡略化されたDOCTYPE宣言だけを書きます。
<!DOCTYPE html>
これまでは文書型として、厳密型(strict)、移行型(transitional)、フレーム(frameset)の3つがHTML 4.01やXHTML 1.0にありました。しかし、HTML5ではフレームは廃止され、また以前には非推奨とされていた要素HTML5ではfont、basefont、u、s、strike、acronym、tt、big、applet、isindex、center、dir、frame、frameset、noframesの各要素が廃止されているや属性も廃止されたので、移行型もありません。そして、互換性をどのように担保するかを含めて、仕様全体はHTML5内部で決められています。もはやDTDはいらない、というわけです。それは一方で、XHTML 1.1のように、仕様に対して厳密にコードを書くしかないということです。
では、HTMLとXHTMLの区別は無くなったのでしょうか? これは、HTML、XMLの、いずれかの形式にデータを変換するという意味で「シリアライゼーション」と呼ばれていますが、ようはHTMLをXMLの書式に合わせて書いたものがXHTMLです。それをXML宣言やDOCTYPE宣言のバージョンで明示していたわけですが、HTML5では、中身の書き方次第でどちらにもできる、ということになっています。つまり、XMLの規則に従ってコードを書けば、「XHTML」になるということです。もっとも身近なXML規則は、「必ず終了タグが必要」というもので、img要素のような空要素は、次のように書きます。
<img alt="" src="URIアドレス" />
なお、このタグの閉じ方は、XHTMLではないただのHTML(HTMLシリアライゼーション)でも、HTML5では利用することができます。私自身は、これまでXHTML 1.1でコードを書いてきたので、当サイトの記述では「/>」をそのまま使っています。
もちろん、「/>」を使っただけでは、XHTMLにはなりません。XHTML 1.1などのように、html要素に以下の属性を記述する必要もあります。
<html xml:lang="ja" xmlns="https://www.w3.org/1999/xhtml">
なお、IE 9でのXHTMLシリアライゼーションにはまだ不明確な点があるので、当サイトでは「/>」を使っているものの、HTMLシリアライゼーションとしてHTML文書を記述しています。
メタデータ
従来のHTML/XHTMLでは、head要素内にmeta要素でMIMEタイプと文字コードを明示してきました。
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
もしくは
<meta http-equiv="Content-Type" content="application/xhtml+xml; charset=utf-8" />
といった記述です。このうち、MIMEタイプは選択したシリアライゼーションによって決定されるようで、http-equivとcontent属性の組み合わせによる記述は、互換性のためのみに残されています。とはいえ、文字コードを明示しないと文字化けする場合があるので、HTML5では次のように文字コードの記述を独立して行うようになりました。
<meta charset="UTF-8" />
IE互換表示のメタスイッチ
ところで、現状でW3Cの「W3C Markup Validation Service」で構文チェックを行うと、次のコードはエラーになります。
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
X-UA-Compatibleは、IE独自の互換表示Internet Explorerの「ブラウザ モード」。他のブラウザにも存在する表示モード(標準モード/後方互換モード)とはまた別に、IE 7以前のブラウザ固有の表示方法に準拠(EmulateIE7 モード)するか、表示方法をより標準(CSS Level2.1、3、Selectors API)に準拠させるかを選択する。X-UA-Compatibleと対になるcontent属性の値を「IE=8」「IE=9」などとすることで、IE各バージョンが対応する最大限の標準準拠性能に従うことになる。なお「IE=edge」は、最新バージョンの最大限の性能に合わせる、という指定になるを指定するに使います。この機能は、IE 9にも実装されています。互換表示のオン/オフはユーザーが切り替えられますが、HTMLページ側で互換表示の可否を指定できるのが、X-UA-Compatibleです。

こうした、ブラウザ固有の設定は、現状では認められていないようです。私は、よりWeb標準に即した表示にするため、互換表示をオフにし最新IEの表示機能を使うIE=edgeを指定してきましたが、HTML5では、それができなくなってしまいました。
IE 8、9には、互換表示を自動的に切り替えるため、Microsoftが互換表示を使用するWebサイトの一覧をWindowsアップデートで提供し、その情報に基づいて互換表示のオン/オフをブラウザが決定する機能この機能がオンになっている場合、アドレスバーに「互換表示」ボタンは表示されないもあります。デフォルトでは、この機能が有効になっています。そのため、Webサイトを設置したプロバイダがこの一覧に含まれていたなら、X-UA-Compatibleで目的のWebページを互換表示から除外させることができたのです。それが駄目になったということは、以下の設定で、この一覧の利用を無効にするしかありません。
- IEを起動
- [Alt]キーを押してメニューバーを表示
- メニューバー「ツール」-「互換表示設定」をクリック、「互換表示設定」ダイアログを開く
- 「マイクロソフトからの更新されたWebサイト一覧を含める」をクリック、チェックを外す
- 「閉じる」をクリック、ダイアログを閉じる
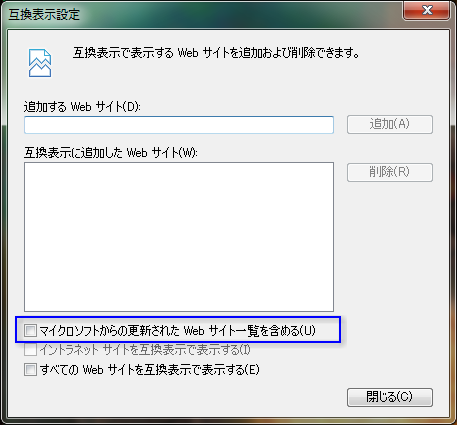
なお、現状のIE 9「Platform Preview #7」では、IE 8もしくはIE 9 Betaでこの一覧利用を無効にし、なおかつ互換表示をオフにしておかないと、当サイトのSVG画像ファイルの表示が正しく行われません。
メタデータ名
この他、従来のmeta要素ではname属性を使っていくつかの付属情報(メタデータ名)を定義できましたが、HTML5では、今のところ仕様で明示されている値は以下の通りです。
- application-name
- ページがWebアプリケーションである場合のWebアプリケーション名IE 9の「ピン」機能でページをWindows 7のタスクバーに固定する場合、このapplication-nameを使用している
- author
- 著者名
- description
- ページの説明
- generator
- ページを生成したソフトウェアパッケージ
- keywords
- ページのキーワード
これら以外のメタデータ名は、「WHATWG Wiki MetaExtensions page」に提案することになっているようです。
基本構造のまとめ
ここまでの、HTMLシリアライゼーションとしての書き方をまとめると、HTML5では、文書の最小限の基本構造は次のとおりに書くことになります。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8" />
<title>タイトル</title>
</head>
<body>
</body>
</html>
セクション
さて、文章を書く場合、みなさんは「アウトライン」を意識しているでしょうか? 文章のアウトラインは、一般的には見出しによって構成されます。その見出しには、大見出し、小見出しといったレベルがあり、HTMLでは1~6段階、Microsoft Wordでは1~9段階まで用意されています。
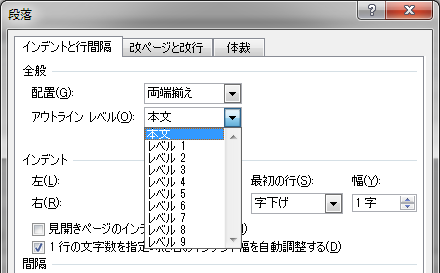

この文章もそうなのですが、文章内容を意味のまとまりでグループ化し、それをWindowsのフォルダのように階層化したものが、アウトラインです。Wordでは、2007までは「見出しマップ」として、2010では「ナビゲーション」として、このアウトラインを確認することができます。アウトラインが適切に指定されたPDF文書であれば、Adobe Readerの「しおり」でも、同様に確認できます。HTMLは「文書構造を定義するもの」とよく言われますが、その基本は、アウトラインで文章を分かりやすくまとめるということに他なりません。
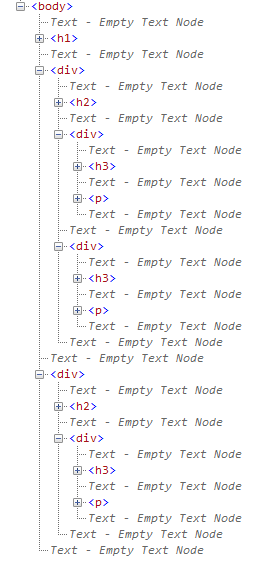
Wordで文章に見出しを付けると、それが階層構造で表されるのは、見出しにアウトラインレベルという9段階の数値があらかじめ設定されているからです。では、HTMLの見出しはどうでしょうか? こちらはh1~h6というように、要素名に数値が付けられ、アウトラインレベルを表しています。
また、見出しだけでなく、HTMLの各要素も、その入れ子構造に従って階層で管理され、IE 8や9では「開発者ツール」IE 8以降で、ブラウザに内蔵されている解析ツール。[F12]キーで起動できるを使いDOMツリーという形式で階層を確認できます。しかし、例えばbody要素の直下にh1~h6要素を順々に記述しても、これらの要素はDOMツリーで階層構造にはなりません。
<body>
<h1>見出し1</h1>
<h2>見出し2</h2>
<h3>見出し3</h3>
<h4>見出し4</h4>
<h5>見出し5</h5>
<h6>見出し6</h6>
</body>
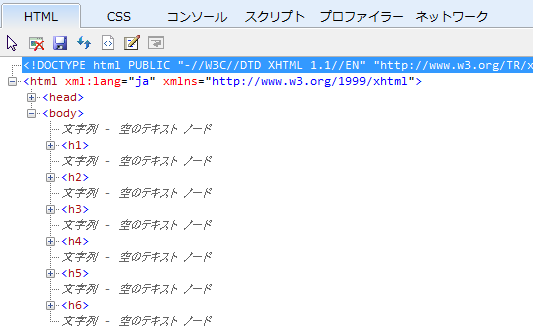
Wordなどワープロの文書では、このように見出しを並べて書くと、「ナビゲーション」等で見られるとおり、きちんと階層化してくれます。なぜ、HTML文書ではダメなのでしょうか? それは当然といえば当然で、DOMツリーの階層は、要素の入れ子関係によってのみ表されるからです。さきに触れたように、h1~h6の見出しコンテンツには、要素内容としてフレーズ・コンテンツしか入りません。端的に言えば、h1要素の中にh2要素やp要素を入れることはできません。ですから親要素が同じなら、これらの要素は、見た目では同じアウトラインレベルとしてツリーに表示されます。
section要素
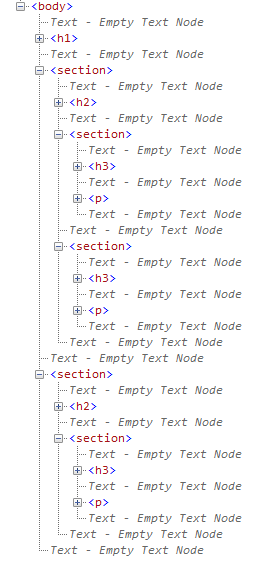
HTML5では、このアウトラインレベルを定義するものとして、セクションという概念が導入されました。この概念に従えば、見出しの要素はその1~6の番号によって、たとえツリー表示にならなくても、「暗黙のセクション」による階層が存在するということになっています。しかし、「暗黙」は人間がそれとなく理解するもので、データ上の根拠が不明確です。そこで、こうした階層構造を作成する要素のひとつとして、section要素が新設されました。例えば、見出し1~3で文書構造を定義するのであれば、
<body>
<h1>見出し1</h1>
<section>
<h2>見出し2①</h2>
<section>
<h3>見出し3①</h3>
<p>本文</p>
</section>
<section>
<h3>見出し3②</h3>
<p>本文</p>
</section>
</section>
<section>
<h2>見出し2②</h2>
<section>
<h3>見出し3③</h3>
<p>本文</p>
</section>
</section>
</body>
というsection要素の入れ子関係によって、次のようなアウトラインを明示的に構成HTML5で生成されるアウトラインは、「HTML 5 Outliner」というWebサイトで確認できるできます。
- 見出し1(タイトル)
- 見出し2①(章)
- 見出し3①(節)
- 見出し3②(節)
- 見出し2②(章)
- 見出し3③(節)
- 見出し2①(章)
この構成の場合、最上位レベルのh1要素がページのタイトル、第2レベルのh2要素が「章」、第3レベルのh3要素が「節」になっているといえるでしょう。ですから、最も親のsection要素が「章」、その入れ子のsection要素は「節」を定義すると捉えることもできます。
なお、次のように、h1要素も囲むsection要素を書いてしまうと、階層がひとつ増えてしまいます。これは、body要素が最上位のセクションとして存在しているからです。
<body>
<section>
<h1>見出し1</h1>
<section>
<h2>見出し2①</h2>
<section>
<h3>見出し3①</h3>
<p>本文</p>
</section>
<section>
<h3>見出し3②</h3>
<p>本文</p>
</section>
</section>
<section>
<h2>見出し2②</h2>
<section>
<h3>見出し3③</h3>
<p>本文</p>
</section>
</section>
</section>
</body>
- Untitled Section
- 見出し1
- 見出し2①
- 見出し3①
- 見出し3②
- 見出し2②
- 見出し3③
- 見出し2①
- 見出し1
body要素は、フロー・コンテンツを入れる最上位の要素なので、自らがセクションになるセクショニング・ルートセクショニング・ルートとして扱われるのは、body要素のほかに、blockquote、figure、td、fieldset、detailsの各要素という扱いになります。まあ、セクションの元締めということですが、ここまで細かく分類されると、うんざりしてきます。
それはそれとして、この場合、body要素が表すトップセクションには見だし要素が何も入っていないので、トップセクションは「見出し無し」(Untitled Section)と認識されます。このため、原則的としてsection要素にはそのアウトラインレベルを表す見出し要素を入れることになっています。
hgroup要素
さて、エッセー「第2章」を実例にとって見ると、次のようにアウトラインを構成しています。
- 第2章
- サイトナビゲーション
- 80年代前半
- ルーツを求めて
- 60年代の音
- キンクス
- デヴィッド・ボウイ
- パンクロック
- クラッシュ
- ストラングラーズ
- 限りある情報を求めて
- 輸入盤専門店の巡礼
- 目次リスト
- 脚注
このエッセー「第2章」では、実際にはh1要素「第2章」の次に、h2要素「魅惑と幻惑に彩られた出発」が入っています。
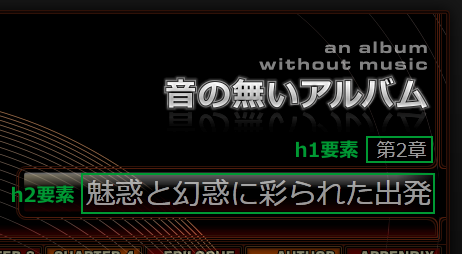
しかし、このh2要素はアウトラインに現れていません。その秘密は、この2つの要素をhgroup要素で囲んでいるからです。
<hgroup>
<h1>第2章</h1>
<h2>魅惑と幻惑に彩られた出発</h2>
</hgroup>
hgroup要素は、その名の通り見出しをグループ化します。グループ化された見出しは、その中でレベルが上位の見出し(この場合はh1)だけがアウトラインに認識され、他は無視されます。ここでのh2要素は、文書構造的にはh1要素のサブタイトルという扱いです。こうしたサブタイトルは、従来であれば見出し以外の要素で入れるとか、見出し内をbr要素で改行して入れるといった、すっきりしない方法に頼るしかありませんでした。しかし、HTML5では、見出しのようでいて見出しでないものをhgroup要素内に定義することで、このうやむや感を解決してくれます。
たかが見出しの扱いぐらいに、色々と細かいところまで目配りして来ましたが、私は、章や節による構成を念頭に置いて文章を書いているので、section要素による定義は、親和性が高いというか、私の「作文の仕方」にとって馴染み深いものです。しかし、ちょっとした記事とか、商品一覧といったページに、ここまでのアウトラインレベルによる階層化は必要ないでしょう。いくらHTML5でsection要素が新設されたからとか、セクショニングがHTML5の重要な概念だと焚きつけられたからといって、アウトラインを構成する必要の無い文章にまで、無理にそれを適用しなくてもよいと思います。まあ、論文調の文章を書くつもりはない、見出しの階層なんて興味がない、サブタイトルがどんな要素だって関係ない、という方は、section要素の使い方で悩むこともないでしょう。
コンテンツの構成
そんなsection要素やhgroup要素よりも、HTML5で人の目を惹くとしたら、次の新設要素が挙げられるでしょう。
- header
- nav
- article
- aside
- footer
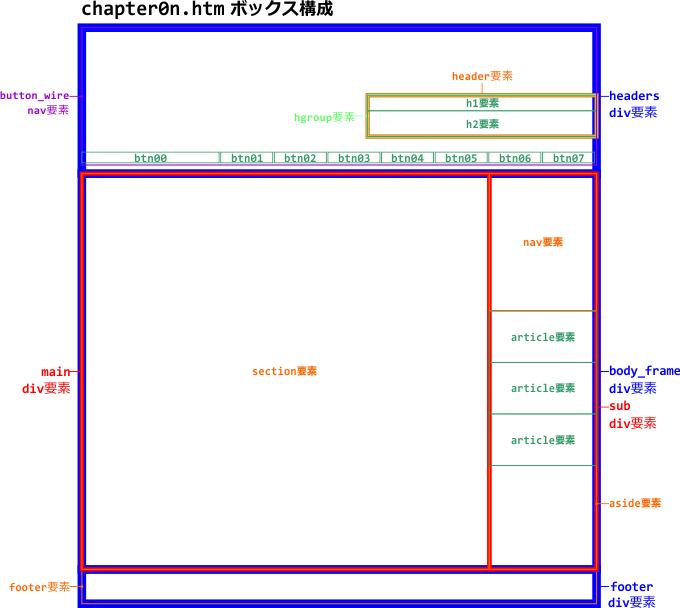
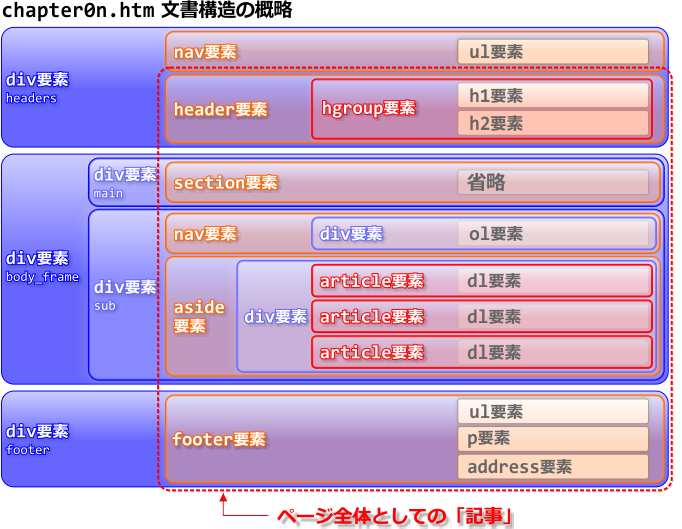
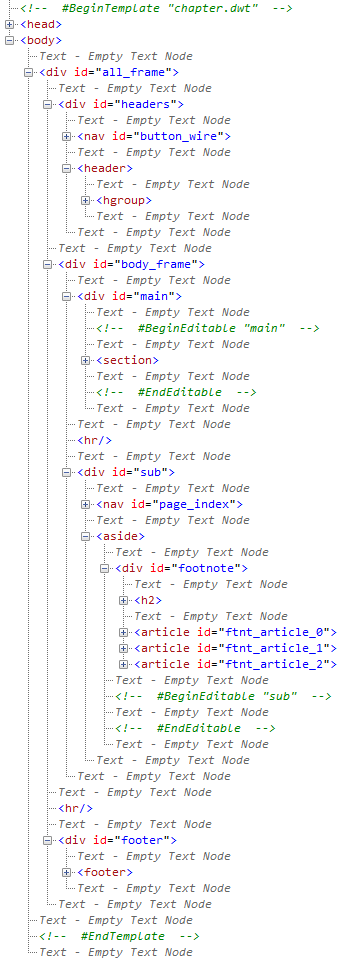
これらはフロー・コンテンツであり、nav、article、aside要素はセクション・コンテンツでもあります。header、footer要素は、その言葉通りのヘッダとフッタを表し、nav要素はナビゲーション、article要素は記事、aside要素は余談といった意味を持つ要素です。一見すると、これらは基本的なWebページの構成要素のようです。実際、先に紹介した、エッセー「第2章」のページは、従来の手法であれば、以下の「headers」「main」「sub」「footer」という領域をdiv要素で定義してきましたが、見た目上はこれらを新要素で置き換えられそうです。
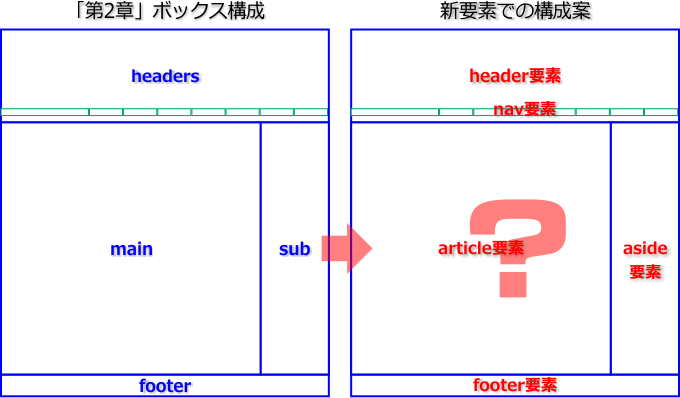
しかしHTML5は、こうした素朴な解釈を認めてはくれません。まず、注意しなければならない点は、article要素の扱いです。この要素は、ひとつの独立した記事を定義します。「第2章」のmain領域にある文章は、たしかにひとつの独立した記事に違いはありません。しかし、headers領域のh1要素「第2章」は、main領域の記事のタイトルであり、これらは不可分のものです。つまり、main領域にある文章は、独立してはいないのです。では、headers領域も含めて、article要素にすべきでしょうか?
今回、ページトップのタイトル部分はheader要素、ページ下部の著者名等が入った部分はfooter要素で定義しています。そしてこれらは、article要素の中に収めることも可能です。それについては問題ありませんが、article要素はセクション・コンテンツです。ページ全体をarticle要素で囲むと、最上位のセクションであるbody要素との間に、「Untitled Section」がひとつ生まれることになってしまいます。これは、先に触れた、body要素の直下にsection要素を入れた場合と同じです。つまり、ページ全体は最初からひとつの「記事」であり、それと同じものをarticle要素で二重に定義する意味はないのです。
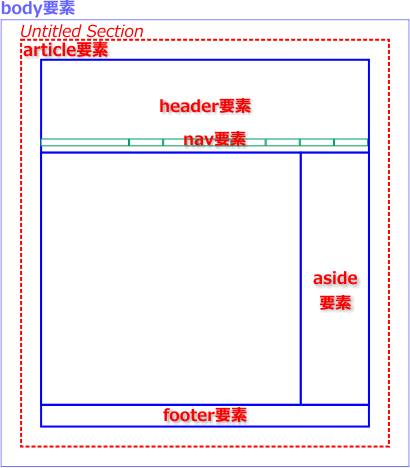
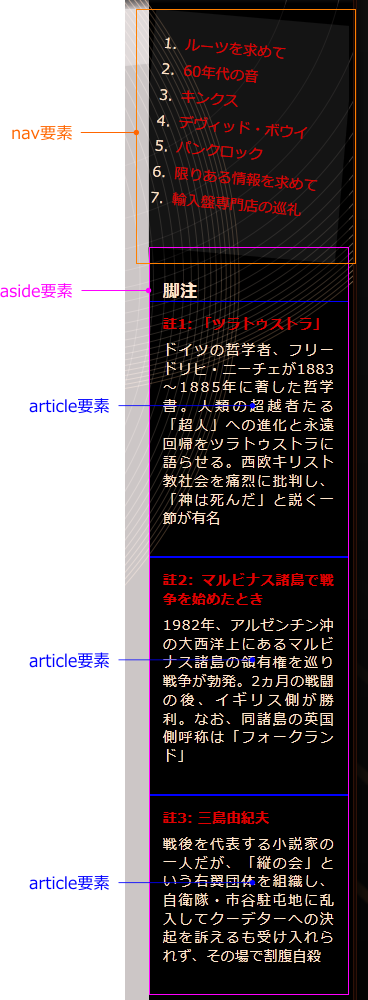
では、「第2章」ページでarticle要素にする部分は他にあるでしょうか? 私は、脚注の3つの文章を、それぞれarticle要素で囲みました。これらは、本文からは独立した個別の内容だからです。また、これらのarticle要素は、h2要素「脚注」を見出しとする、ひとつのセクションで区切られています。それが、aside要素です。本文とは関連性の薄い内容を、この要素で囲むということなので「余談」と呼びましたが、脚注が余談かどうかは、まあ、判断が難しいところです。これが、ページ内のアフィリエイト広告などであれば、aside要素と断定できるでしょう。いや、広告だって本文と関連性があれば、article要素でよいかもしれません…。ここでの脚注も、本文との関連性はそれなりあるわけですから、余談ではなくただの独立記事(article要素)でよいのかもしれません。
また、ページの大枠としては、本文のmain領域と、sub領域を2つに分けているわけですが、感覚的にはsub=asideは一致します。そして、脚注の上にあるのが、このページのナビゲーションです。ですから、nav要素で囲むのは正しいでしょう。では、このnav要素をaside要素内に含めるべきでしょうか? aside要素は、nav要素をグループ化することにも使えるとされています。しかし、サイトのナビゲーションであれば、このページの本文との関連性は薄いでしょうが、ページのナビゲーションは本文の見出しの要約でもあり、なおかつ独立した記事というわけでもなく、本文への依存性は高いと言えます。そのような訳で、このnav要素はaside要素の外に出してあります。結果として、このページは視覚的にmain領域とsub領域の2つに分割されているものの、それらと単純に一致するarticleとaside要素の文書構造にはなっていません。
また、サイトのナビゲーションはheaders領域に入れてありますが、header要素の外で、nav要素として独立セクションになっています。これと同じリンクが、ページ下のfooter領域にもありますが、こちらはnav要素にはしてありません。それは、nav要素はページ内の主要なナビゲーションを定義するものとされているからです。同じ内容のナビゲーションがあるなら、そのうちのひとつをnav要素で定義しておけばよいということです。
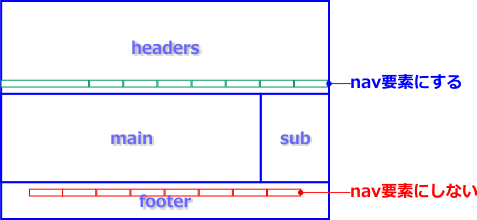
このように、ページの構成を単純にheader、nav、article、aside、footerで定義するというものではないことが、お分かりいただけたでしょうか?
セクションとレイアウト
また、レイアウトという観点からも、ページの見た目の構成をこうした要素だけで実現することには、いくつかの問題があります。
その根本的な理由は、文書構造上の意味を持つ要素をデザイン用途に使ってはいけないという、HTMLの原則的な前提です。header、nav、article、aside、footer、そしてsectionといった要素は、それらが区切る範囲に意味を与えます。意味付けするということが目的であって、これらの要素はレイアウトのために存在するのではありません。table要素をレイアウト目的で利用する、いわゆるレイアウトテーブルが、Web標準では既に退けられているのと同じ理由です。
また、HTML5に対応していない、旧いブラウザに対する配慮においても、こうした要素に対するスタイル指定には、注意が必要です。現状では、IE 9や他の最新ブラウザを含め、ほとんどのブラウザはHTML5で新設された要素を、インラインで表示します。つまり、デフォルトでdisplay:inlineが指定されているようなものです。ですから、そのままでは幅(width)や高さ(height)を適用できません。まあ、この問題は、次のようなスタイルシートを読み込ませれば解決します。
section, header, article, footer, aside, nav, hgroup, figure, figcaption {
display: block;
width: auto;
height: auto;
}
これで最新ブラウザは大丈夫なのですが、IE 8以下には問題が残っています。IE 8以下では、HTML5の新設要素は、意味不明の「未知の要素」ということになります。そして、未知の要素では、DOMツリーが正しく構成されません。
section要素を例に挙げてみると、その開始タグは空要素として閉じられてしまいます(<section />)。終了タグはといえば、「</section />」といったように、やはりこちらも謎めいた空要素の開始タグとして認識されています。
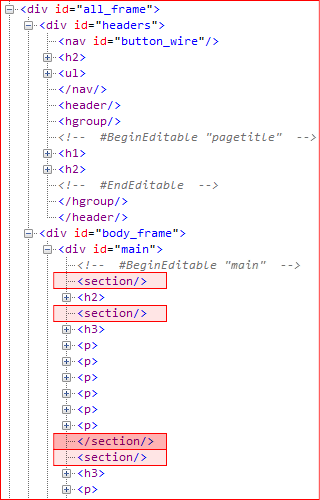
この結果、section要素の囲みは崩れ、暗黙どころか物理的な入れ子関係が解消されてしまっています。スタイルは要素単位で適用しますから、その範囲が違ってしまったら、指定通りには適用されなくなります。
この問題を解決するには、JavaScriptを使用して、IE 8以下が未知の要素を生成する手助けをします。
(function () {
var ELEMENT = new Array("section","header","article","footer","aside","nav","hgroup","figure","figcaption","time","mark","canvas","video","audio","source");
var MAX = ELEMENT.length;
for (var i=0; i<MAX; i++) {
document.createElement(ELEMENT[i]);
}
}) ();
このスクリプトでは、createElementメソッドで未知の要素(HTML5の新要素)を作成しています。ただし、これをonloadなどのイベントで実行するのではなく、「無名関数」をそのまま実行させる方法でHTMLファイルに読み込ませます。
すると、IE8以下でも、未知の要素がソースコードから読み取られる際に、正しくDOMツリーが構成されるようになります。
ただし、当然ですが、JavaScriptがオフになっていると、この解決策は効き目がありません。JavaScriptを正しく実行するために正しいDOMツリーを作る、という目的であれば、スクリプトが無効の場合、正しく実行させたいスクリプトも実行されないわけですから、DOMツリーがどうなっていようと構いません。しかし、スタイルシートは、スクリプトとは関係なく処理されます。スクリプトが無効であれば、(IE 8以下では)正しいDOMツリーを作ることができず、しかしスタイルシートは別途処理され、適用に失敗することになります。たしかに、それは限定された条件ですが、無に近い可能性ではありません。
以上の点から、レイアウトの基本的な構成には、従来どおり、div要素やspan要素を使うべきでしょう。先に触れた「第2章」ページも、その他のページも、レイアウトのためのボックス構成は、基本的にdiv要素を使用しています。
ビデオ
ここまでは、主として文書構造に関する小難しい話に終始してきたので、趣向を変えて、HTML5の目新しさの代表であるvideo要素を取り上げてみましょう。この要素は、当サイトのトップページ「社会・政治的背景」内に組み込んであります。
<p><video width="640" height="480" controls="controls" poster="images/trotsky_poster.png">
<source src="https://krzm.jpimages/trotsky.mp4" type="video/mp4" />
<img alt="" src="images/trotsky_poster.png" width="640" height="480" /><br />
この動画は、コーデックがH.264-MAIN(映像)、AAC(音声)のMP4ファイルです。このブラウザでは再生できません。
</video></p>
ここでは、video要素にサイズの指定と再生コントロールの表示(controls属性)、動画再生までの待機時間に表示させる画像(poster属性)を指定しています。肝心の動画ファイルは、video要素の開始タグで、src属性を使って指定することもできますが、上記の例ではvideo要素内に子要素として入れたsource要素で、ファイルのアドレスを指定し読み込ませています。
source要素を使うと、ひとつのvideo要素に複数の動画ファイルを指定することができます。source要素は、video要素内に複数記述できるからです。といっても、それは、いくつもの動画を連続して再生させるためのものではありません。動画ファイルにもいくつかの形式がありますが、それをデータ化した方法(CODEC)にブラウザが対応していないと、再生することはできません。そして、HTML5では、標準のCODECは決められず、以下の「2陣営」に分裂してしまっています。
| ブラウザ | 映像用 | 音声用 | ファイル形式 |
|---|---|---|---|
| IE 9 Beta | H264 | AAC | MP4 |
| Google Chrome | H264、Theora | AAC、Vorbis | MP4、Ogg |
| Safari | H264 | AAC | MP4 |
| Opera | Theora | Vorbis | Ogg |
| Firefox | Theora | Vorbis | Ogg |
まあ、Google Chromeはコウモリのようですが、AppleとMicrosoftは「H264+AAC」、FirefoxとOperaは「Theora+Vorbis最新の動向では、Theora+Vorbisのファイル形式であるOggは放棄され、googleがオープンソースとして開発している「WebM」への移行が始まっている。Firefox、OperaはWebMに対応。googleが開発元であるChromeブラウザでは、H264対応を打ち切り、WebMに一本化。一方、IE9は、WebMのCODECを別途インストールすれば対応するとしているが、ブラウザ自体としてはH264対応を堅持している」と大別できるでしょう。Microsoftを外したWHATWGの仲良しグループも、それぞれの利害が関わってくると話はまとまらないようです。情けないですね。そこでMicrosoftは、この分裂を広げるような形で、「H264+AAC」を採用したのかもしれません。
それはそれとして、これら2種類のファイルに対応するためには、それぞれの動画ファイルを用意し、source要素で個別に記述します。するとブラウザは、それらのうちから自分が対応できる形式のファイルを再生する、という次第です。
トップページに用意した動画は、H264+AACのMP4ファイルです。元々は、Corel R.A.V.E.でFlash用に作ったベクトルアニメーションだったのですが、それを一旦無圧縮のAVIファイルに書き出し、Corel VideoStudio Ultimate X3で加工したうえで、H264+AACにエンコードしました。手元には、Theora+Vorbisに対応した動画編集ソフトがなかったので、今回はIE 9、Safari、Chromeでしか表示できません。ただし、ビデオに映る文字などの輪郭は、IE 9ではスムーズに表示されるものの、Safari、Chromeではギザギザが目立ちます。GPUのハードウェアアクセラレーションを誰よりも活用できているIE 9の再生機能は、Safari、Chromeに勝っているのです。

一方、今回対応ファイルを用意できなかったFirefoxとOperaの場合は、video要素のposter属性で指定した画像が、代替表示されることになります。また、video要素の中には、source要素のほかに、p要素による文章と、img要素による画像を入れてあります。これらは、video要素そのものに対応していないブラウザで、動画の代わりに表示されることになります。
では、ここにFlashムービーをobject要素やembed要素(embed要素はHTML5で正式採用されました)で入れてあげれば、すべてのブラウザで動画を表示できる環境を作り出せるのではないでしょうか? 確かにその通りなのですが、すると、MP4(H264+AAC)、Ogg(Theora+Vorbis)、そしてFLV(Flash)の、3つの動画ファイルを用意しなくてはなりません。しかし、それならば、FLVだけを使えば、現状ではほとんどのブラウザで動画を再生できることになります。別にAdobeやFlashの肩を持つつもりはありませんが、video要素の現状は、こんなものだということです。
政治的考察
ここまで、HTML5でのコーディングについて、私的見解を交えつつも技術的に評価してきましたが、総論的には、「利用する前に思い浮かべていたものと現実の仕様や定義の間には、大きな開きがあった」、という感想を持ちました。まあ、video要素の問題は、動画にあまり関心がない私にはどうでもよいことですが、とりわけセクションの捉え方については、厳密な文書構造が好きな私にとっても、難解な印象を受ける部分が多々ありました。
解釈と訓練
今まで述べてきたほかにも、たとえばHTML5では、strong要素の位置づけが変わり、さらにmark要素が新設されました。これに従来要素を加えると、以下のようなインライン(フレーズ・コンテンツ)での文書構造の定義が、HTML5では多彩に用意されています。
- em要素(従来通り)
- 強調
- strong要素(従来の定義から変更)
- 重要
- mark要素(新要素)
- 注目。もしくは引用部分での強調
- b要素(従来の定義から変更)
- 一般に太字にすべき部分
- small要素(従来の定義から変更)
- 一般に文字を小さくすべき部分
- i要素
- 一般に斜体にすべき部分
しかし、強調と重要の違いとは、いったい何でしょうか? 重要なところは強調したくなると思います。また、注目すべき部分とは...。いちおう、当サイトのページでは、本文中の脚注のある文字列を、mark要素で定義しています。それらの言葉は、「本文全体の脈絡の中ではそれ自体が重要なのではなく、強調するほどでもないけれど、本文内容への理解を深めるため脚注として解説を付けてあるので、そこに注目してほしい」、という理由を考え抜いた上でのことです。私自身の言語活動を吟味し、HTMLの要素に適合するように(HTMLという言語に適合するように)、自らの言葉を再構成するという作業、もしくは訓練です。
さらに、セクションは正しく区切られているのか、コンテンツ・モデルの関係は正しく定義されているのか、などに頭を悩ませていると、ふと、人間が、自分自身が、好きなように言葉を操ればいいのではないか、なぜ、こんな仕様に束縛されなければいけないのか、という疑念が頭をよぎります。
もちろん、セクションという構造は、文章を他人に分かりやすく伝えるため、もしくは論理的に伝えるために、これまで人間が編み出してきた言葉の文化です。それを念頭に置けば、明確な文書構造を探求するということは、「人にやさしく」という理想かもしれません。そのために、私たちは言葉や文章の意味付けを吟味し、内容に見合ったタグを付けられるように、自身の言語を訓練していくのです。友愛に基づく欲望を刺戟とした、思考活動といえるかもしれません。
機械との対峙
一方で、こうしたセクション構造は、検索サイトのロボットが、ページを効率よく分析でき、検索サイトのインデックスを作成するのに役立つという考え方もあるようです。機械的プログラムはまだ人間の思考のように柔軟ではないので、「暗黙のセクション」など理解できません。ですから、与えるデータをきちんと人間が整理してあげましょう、ということです。そこでは、経済的利益の追求が刺戟として機能しています。現在でも、そうした方向性から検索エンジン最適化(SEO)という概念(と商売)が生まれて隆盛を誇っているのですから、HTML5が普及すれば、それに対応したSEOが追求されるに違いありません。
そうした流れに対し、人間が機械(検索エンジン)に振り回されているのではないか、というモダンタイムス的な見解も生まれるでしょう。しかし、私たちは機械への従属とは次元の異なる潮流に飲み込まれているのかもしれません。たとえばSEOのような操作は、人間の生き生きとした、積極的な欲望によって推し進められています。その積極性は、突き詰めれば金銭的欲望です。欲望を満足させられるような言葉を、より効率的に話すことができるように、SEOを通じて私たちは自らを訓練しているのです。続いて、それに見合った言葉が、たとえばHTML5の中で開発されると、言葉は次の刺戟を生み、細分化され、訓練も継続されます。
金銭的欲望に基づく言葉
たとえば、aside要素は、「余談」として本文の外に広告を定義できます。これは、本文から広告を排除するかのようですが、検索エンジンが自社の提供した広告の中身をインデックス化しても、無駄と考えているのかもしれません。実際、こうした広告の大手であるGoogle社が、HTML5を後押ししているのですから。
先に解説したsection要素にしても、ただDOMツリーに階層構造を生成するだけであれば、従来からあるdiv要素を使うことで実現できます。
<body>
<h1>見出し1</h1>
<div>
<h2>見出し2①</h2>
<div>
<h3>見出し3①</h3>
<p>本文</p>
</div>
<div>
<h3>見出し3②</h3>
<p>本文</p>
</div>
</div>
<div>
<h2>見出し2②</h2>
<div>
<h3>見出し3③</h3>
<p>本文</p>
</div>
</div>
</body>
しかしdiv要素には、文書構造的な「意味」がありません。つまり、div要素によって作られた階層からは、「意図」を汲み取ることができないのです。新たに登場した(もしくは敢えて登場させられた)section要素は、無目的な階層に「意味」を与えることが目的となります。その結果、たとえばdiv要素による階層は無視し、section要素や他のセクション・コンテンツ要素の階層からは、その種別と階層レベルを判定して、インデックスとして抽出する見出しを選択するといったことが、検索ロボットによって行われるでしょう。そこでは、「どのような動機に基づいて階層の意味付けを行うのか、その作業に介在する権力の戦略は何か」が、問われてきます。
そしてSEOの手法などが、より厳密にaside要素やsection要素等の利用法を定義し、なおかつ「効率的」な本文のセクション化を教示して行くなら、人々は、本文で検索エンジンの「耳」によりよく響き渡る言葉を、一生懸命に探し、工夫し、それまでの言い回しを改め、さらには他の人々に広めていくでしょう。当然、そうした言葉によって規定される世界は、金銭的欲望の追求に沿ったものになります。アクセシビリティも、例外ではありません。こうして、我々は、金銭的欲望を基準に張り巡らされた蜘蛛の糸に捕捉され、その線に沿って思考し、その網目に似合った人間を自らが生政治的レベルで作り上げていくのです。
インターネットは、知的労働の拡大とそのグローバリズム的展開によって、全世界の津々浦々に染み渡り、資本主義的人間の意識を鍛え再生産する、しかも柔軟な支配構造です。そこでは、規定された仕様に当てはまる言葉を選んでいるときも、自由闊達に喋っている言葉すらも、意識の内部に形成された資本主義的人間の像を塑造するように、言葉は紡がれているのです。
HTML5の記述において、機械プログラムに正しく解釈されるセクション、そして文書構造に、自身の思考と言葉を適合させていく努力は、私も、このサイトの作成で積み重ねてきました。また、その過程を「HTML 5 Outliner」や「W3C Markup Validation Service」などの機械プログラムによって評価し、よい結果が出ると安堵し、エラーが出た場合は文書構造的表現を修正してきました。これは、HTMLコーディングの日常風景でしょう。その日常風景において営まれる、人間の思考と会話が、どのような方向付けの下に訓練されていくのか、どのような欲望に基づいて整列されていくのか――結果として、そうした思考と言葉によって編み上げられるネットワークが、そこから再生産されていく社会の姿を、日々形作っていくのです。
私は、友愛に基づく欲望に沿って私の言葉を語るため、ひとつだけ努力をしてみました。それは、アフィリエイト広告及びそれに関連したSEOを、このサイトには導入しなかったということです。もちろん、それはささやかな抵抗ですが。
